2006/08/10
Problems running Java applets? If you have Windows 7, go to Control Panel, search for Java, go to Java Control Panel tab Java, change Java Runtime Environments settings by adding
|
1 |
-Djava.net.preferIPv4Stack=true |
to the runtime parameters. Or try this alternative page of Dye Mixer.
Introduction
Hello, fellow dyer!
If the Dye Mixer won't start within a couple of minutes, your browser probably doesn't support Java and you need Java plug-in 1.1 (or later) for your WWW browser. You may need to restart the browser after installation.

The basic idea of the Dye Mixer is to let you to try out various dye combinations on various canvases under various lighting conditions, in "virtual reality", with only virtual fabric and dye wasted. :-)
Instructions
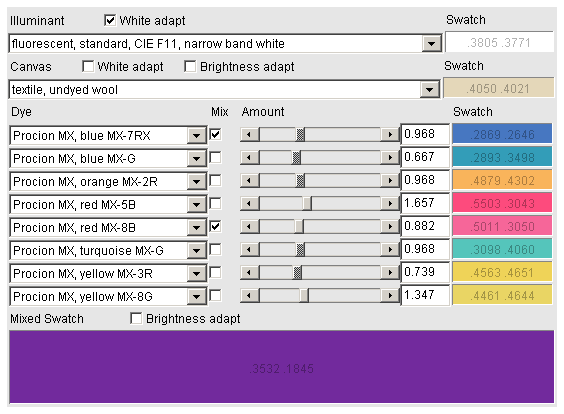
Here are descriptions of the different parts of the Dye Mixer user interface:
- You can alter the virtual lighting conditions by choosing the appropriate Illuminant. Objects appear a different color under different illuminants, so make a choice similar to what you have where your work will be viewed in.
- Illuminant Swatch shows the appearance of the illuminantion on a truly white surface. Each Swatch shows its CIE xy color coordinates.
- Checking Illuminant White adapt makes the illumination appear the same color as the white on your computer screen, to which your vision has adapted to. This will make subjective color evaluation easier. However, if you want to compare absolute colors by holding an object against the computer screen, you should uncheck Illuminant White adapt.
- Before proceeding to dyes, you must choose the Canvas. Dyes appear different color on different canvases.
- Canvas Swatch shows the appearance of the canvas in the chosen illumination.
- Checking Canvas White adapt makes the canvas appear the same color as the white on your computer screen. This may be useful if you have a large canvas, to which your vision adapts, and a small dyed area, and you want to see how the dyed area appears in the context of its surroundings. To view absolute colors, uncheck Canvas White adapt.
- Checking Canvas Brightness adapt increases the amount of light the canvas is exposed to, but does not interfere with the absolute tone of color. Canvas Brightness adapt has no effect if Canvas White adapt is enabled.
- The Dye Mixer allows mixing 8 dyes simultaneously. For each dye:
- Choose the Dye you want to use. Note that the Dye Mixer is ignorant of the chemical compatibility of different dyes and canvases.
- Checking Mix will include the dye in the combined mixture of dyes.
- Amount of dye can be changed either by operating the slider, or numerically. The actual amount or concentration of dye required for the same effect in the laboratory can be direcly proportional to the Amount value. (I'd love to hear your experiments on this!) The proportionality coefficient you must use is different for different dyes and canvases.
- Swatch shows the dyed canvas.
- Mixed swatch shows the canvas dyed with all the selected dyes.
- Checking Mixed swatch Brightness adapt increases the amount of light the dyed canvas is exposed to, but does not interfere with the absolute tone of color.
Here are some typical uses for the Dye Mixer:
- You have a color in the back of your mind and wish to find a dye combination to realize it. Set your computer screen white balance so that it matches the white balance in the space you are in, or just let your eyes adjust to the monitor white balance. Enable Illuminant White adapt. Choose the Canvas and Illuminant as close as possible to what your work will be showed using. Try different dye amounts and combinations until you get an acceptable result. Just to be sure, write down what you are using. Try to use dyes sparingly! In actual reality, for each of the dyes you use in the mix, dye a swatch and see if it gets the same tone of color as the Dye Swatch in the Dye Mixer. Adjust the amount of dye until you have a matching result (see below for matching instructions).
- You want to compare the color of a real-life object to a color produced by the Dye Mixer. Adjust the white balance of your computer screen to 6500 K. Choose an illuminant as close as possible to what you have in the space you are in. Disable white adaptations in the Dye Mixer. Adjust the computer screen contrast and the amout of lighting in your room so that the Dye Mixer's swatch has the same brightness as the object. Compare the colors between the Dye Mixer's swatch and the object.
Happy mixing!
Version history
This is version 1.1 of the Dye Mixer. Some of the older versions are available. The evolution of the Dye Mixer has been as follows (read from bottom to top):
| 1.1 | Plenty of illuminant, canvas and dye data has been added. Most of the data is now in a separate text file, allowing adding new data without recompilation, or updating the Dye Mixer version. The biggest improvement, however, is that now the Dye Mixer is Java 1.1 compatible! This is good because Sun's license for Java 1.2 (used in the Dye Mixer 1.0) and greater is, for some users and browser vendors, unacceptably restrictive. There has been some changes in the scalings of dye amounts - sorry about that if you wrote down some formulas. You can convert the 1.0 amounts to 1.1 notation by a simple calculation. |
| 1.0 | Added sliders and some minor things; improved much on ease of use. |
| 0.9 | Initial version. |
Technical details
The jar package of the applet is made available for download.
The operation of Dye Mixer is spectrum-based. So, adding a new light source, canvas or dye will require measuring the spectrum. I will be happy to add a new dye (or light, or canvas) if you can provide me with its spectrum and as much information of the dye as possible. If you are unable to locate a spectrophotometer, you could also send me a sample of the dye.
The Procion MX dye absorbance spectra were measured with a spectrophotometer from 350 nm to 800 nm at 5 nm steps, using concentrations that kept absorbance under 1.0, with distilled water as solvent. The canvas reflectance spectra were measured with my own mirror apparatus combined with a spectrophotometer, using a tissue paper as white reference. The theoretical light spectra are computed by Dye Mixer and the rest of the spectra were obtained from various sources.
{kind=link}
A simple absorbance model is used with the dyes: The absorbance spectrum of a dye is multiplied by the amount value. This is analogous to increasing the thickness, or concentration, of the dye layer. The model is unable to handle fluorescent materials and dyes.
The CIE XYZ tristimulus coordinates are calculated from the obtained light spectrum and further converted into sRGB for viewing. Java XYZ to sRGB conversion uses CIE D50 instead of CIE D65, so I coded my own according to the sRGB standard. sRGB uses the CIE D65 reference illuminant white point, so you should adjust your monitor and your room lighting to 6500 K color temperature, if you want to view absolute colors and compare samples directly against the picture on the monitor. Normally you should, however, resort to subjective comparison, using the screen white as the white reference for the virtual sample, and the room lighting (as reflected from white walls, paper) as the white referene for the actual sample.
References
The input spectra came from various sources:
- CIE, standards spectra.
- Wenham, S.R., Green, M.A. and Watt, M.E., standards spectra.
- Mitsubishi Electric, illuminant spectra.
- Kobus Barnard, Lindsay Martin, Brian Funt and Adam Coath, illuminant spectra.
- Jouni Haanpalo, dye absorbance spectra.
- Eastman Kodak, reflectance spectra.
- Purdue University, reflectance spectra.
- Noboru Ohta, reflectance spectra.
Links
Here are some related links:
- DyersLIST is a mailing list for dyers.Which Procion MX colors are pure, and which mixtures by Paula Burch is an excellent reference to MX dye names used by different distributors.MatchWizard is a similar software from Clariant, perhaps more interesting for industrial textile dyers.
A bit of background
I got interested in textile dyes after I bought a tie-dye T-shirt at Berkeley, California, which I visited during a "business trip" in spring 2001. I loved the place for it atmosphere, too. I grew fond of colorful hippie clothes, and wanted more. I could not find any locally (in Finland, they hardly even sell T-shirts during winter). The consequence was that I ordered, together with my mother Hanna (I didn't have a credit card) some Procion MX dyes from Quilt und Art, Germany, to dye my own clothes.
Since, I have dyed tens of T-shirts and some other items. Most have been bought by my friends, for small fees certainly not to be of any interest to tax officials... :-)